- 博客(80)
- 收藏
- 关注
 RSS订阅
RSS订阅原创 基于Spark GraphX的图形数据分析
基于Spark GraphX的图形数据分析一、图(Graph)1.1 图(Graph)的基本概念1.2 图的术语1.3 图的经典表示法二、Spark GraphX2.1 简介2.2 GraphX核心抽象三、GraphX API3.1 创建Graph3.2 查看图信息一、图(Graph)为什么需要图计算许多大数据以大规模图或网络的形式呈现许多非图结构的大数据,常会被转换为图模型进行分析图数据结构很好地表达了数据之间的关联性1.1 图(Graph)的基本概念图是由顶点集合(vertex
2020-11-26 15:18:11
 338
338
原创 spark sql 重写sql50道经典题
作者行业新人,如果有不对的地方,希望可以指出,共同学习。确定表名和字段1.学生表Student(s_id,s_name,s_birth,s_sex) --学生编号,学生姓名, 出生年月,学生性别2.课程表Course(c_id,c_name,t_id) – --课程编号, 课程名称, 教师编号3.教师表Teacher(t_id,t_name) --教师编号,教师姓名4.成绩表Score(s_id,c_id,s_score) --学生编号,课程编号,分数建表和插
2020-11-25 12:13:53
438
原创 json日志分析和数据清洗
示例文件json解析json在线文件解析网址解析后文件格式{ "cm": { "ln": "-55.0", "sv": "V2.9.6", "os": "8.0.4", "g": "[email protected]", "mid": "489", "nw": "3G", "l": "es", "vc": "4", "hw": "640*960", "ar": "MX", "uid": "489", "t": "1593123253541", "
2020-11-23 09:04:46
630
原创 Spark分布式计算原理
Spark分布式计算原理一、RDD依赖与DAG工作原理1、RDD的依赖关系2、DAG工作原理二、RDD优化1、RDD持久化1.1、RDD缓存机制cache1.2 检查点2、RDD共享变量2.1、广播变量2.2、累加器3、RDD分区设计4、数据倾斜三、装载常见数据源3.1、装载CSV数据源3.1.1 使用SparkContext3.1.2使用SparkSession3.2、装载JSON数据源一、RDD依赖与DAG工作原理1、RDD的依赖关系1.1 Lineage:血统、遗传RDD最重要的特性之一,
2020-11-12 17:27:46
489
原创 spark RDD算子(十一)之RDD Action 保存操作saveAsTextFile,saveAsSequenceFile,saveAsObjectFile,saveAsHadoopFile 等
saveAsTextFiledef saveAsTextFile(path: String): Unitdef saveAsTextFile(path: String, codec: Class[_ <: CompressionCodec]): UnitsaveAsTextFile用于将RDD以文本文件的格式存储到文件系统中。codec参数可以指定压缩的类名。
2020-11-11 20:03:48
663
原创 spark RDD算子(十二)之RDD 分区操作上mapPartitions, mapPartitionsWithIndex
mapPartitionsmapPartition可以倒过来理解,先partition,再把每个partition进行map函数,适用场景如果在映射的过程中需要频繁创建额外的对象,使用mapPartitions要比map高效的过。比如,将RDD中的所有数据通过JDBC连接写入数据库,如果使用map函数,可能要为每一个元素都创建一个connection,这样开销很大,如果使用mapPartitions,那么只需要针对每一个分区建立一个connection。下面的例子,把每一个元素平方java 每一
2020-11-11 11:19:26
260
原创 spark RDD算子(十)之PairRDD的Action操作countByKey, collectAsMap
countByKeydef countByKey(): Map[K, Long]scala例子val conf = new SparkConf().setMaster("local[*]").setAppName("CountByKey_CollectAsMap_Scala")val sc = new SparkContext(conf)//scala公共代码val rdd = sc.parallelize(List((1,2),(2,4),(2,5),(3,1),(3,9),(3,6)))
2020-11-10 19:33:09
144
 1
1
原创 spark RDD算子(九)之基本的Action操作 first, take, collect, count, countByValue, reduce, aggregate, fold,top
first返回第一个元素scala在这里插入代码片
2020-11-10 19:08:11
240
原创 spark RDD算子(八)之键值对关联操作 subtractByKey, join,fullOuterJoin, rightOuterJoin, leftOuterJoin
subtractByKeydef subtractByKey[W](other: RDD[(K, W)])(implicit arg0: ClassTag[W]): RDD[(K, V)]def subtractByKey[W](other: RDD[(K, W)], numPartitions: Int)(implicit arg0: ClassTag[W]): RDD[(K, V)]def subtractByKey[W](other: RDD[(K, W)], p: Partitioner)
2020-11-10 12:14:02
139
原创 spark RDD算子(七)之键值对分组操作 groupByKey,cogroup
groupByKeydef groupByKey(): RDD[(K, Iterable[V])]def groupByKey(numPartitions: Int): RDD[(K, Iterable[V])]def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]groupByKey会将RDD[key,value] 按照相同的key进行分组,形成RDD[key,Iterable[value]]的形式, 有点类似于sql中
2020-11-10 11:43:22
224
原创 spark RDD算子(六)之键值对聚合操作reduceByKey,foldByKey,排序操作sortByKey
reduceByKeydef reduceByKey(func: (V, V) => V): RDD[(K, V)]def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]接收一个函数,按照相同的key进行reduce操作,类似于scala的reduce的
2020-11-10 10:06:37
542
原创 spark RDD算子(五)之键值对聚合操作 combineByKey
combineByKey简要介绍def combineByKey[C](createCombiner: (V) => C, mergeValue: (C, V) => C, mergeCombiners: (C, C) => C): RDcreateCombiner: combineByKey() 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。如果
2020-11-09 20:08:07
168
原创 spark RDD算子(四)之创建键值对RDD mapToPair flatMapToPair
示例文件:我们在E:\Ideal\sparkdemo1\in\的位置下写入文件sample.txtaa bb cc aa aa aa dd dd ee ee ee eeff aa bb zksee kksee zz zksmapToPair将每一行的第一个单词作为键,1作为value创建pairRDDscala代码scala是没有mapToPair函数的,scala版本只需要map就可以了val conf = new SparkConf().setMaster("local[*]").
2020-11-09 18:38:56
194
原创 spark RDD算子(三) distinct,union,intersection,subtract,cartesian
distinctdistinct用于去重, 我们生成的RDD可能有重复的元素,使用distinct方法可以去掉重复的元素, 不过此方法涉及到混洗,操作开销很大union两个RDD进行合并intersectionRDD1.intersection(RDD2) 返回两个RDD的交集,并且去重intersection 需要混洗数据,比较浪费性能subtractRDD1.subtract(RDD2),返回在RDD1中出现,但是不在RDD2中出现的元素,不去重cartesianRDD1.carte
2020-11-09 16:52:32
315
原创 spark RDD算子(二) filter、map、flatMap
示例文件:我们在E:\Ideal\sparkdemo1\in\的位置下写入文件sample.txtaa bb cc aa aa aa dd dd ee ee ee eeff aa bb zksee kksee zz zksfilter我要将包含zks的行的内容给找出来scala版本val conf = new SparkConf().setMaster("local[*]").setAppName("FilterScala")val sc = SparkContext.getOrCre
2020-11-09 16:23:39
181
原创 spark RDD算子(一) parallelize、makeRDD、textFile
parallelize调用SparkContext 的 parallelize(),将一个存在的集合,变成一个RDD,这种方式试用于学习spark和做一些spark的测试scala版本def parallelize[T](seq: Seq[T], numSlices: Int = defaultParallelism)(implicit arg0: ClassTag[T]): RDD[T]第一个参数一是一个 Seq集合第二个参数是分区数返回的是RDD[T]scala> sc.para
2020-11-09 14:28:49
421
原创 Spark RDD基本理论和常用算子
Spark RDD基本理论和常用算子一、Spark RDD概述1、RDD概念2、RDD和DAG3、RDD的特性和流程4、RDD分区二、RDD的创建1、使用集合创建RDD2、通过加载文件产生RDD三、RDD常用算子1、转换算子a) 基本概论b) 常用的转换算子一、Spark RDD概述1、RDD概念简单的解释RDD是将数据项拆分为多个分区的集合,存储在集群的工作节点上的内存中,并执行正确的操作复杂的解释RDD是用于数据转换的接口RDD指向了存储在HDFS、Cassandra、HBase
2020-11-05 16:13:54
139
原创 spark基础及架构
spark基础及架构一、Spark概论Spark简介一、Spark概论Spark简介诞生于加州大学伯克利分校AMP实验室,是一个基于内存的分布式计算框架发展历程2009年诞生于加州大学伯克利分校AMP实验室2010年正式开源2013年6月正式成为Apache孵化项目2014年2月成为Apache顶级项目2014年5月正式发布Spark 1.0版本2014年10月Spark打破MapReduce保持的排序记录2015年发布了1.3、1.4、1.5版本2016年发布了1.6、2.x
2020-11-04 15:23:39
123
原创 Scala Array常用方法(二)
Scala Array常用方法(二)indexOfdef indexOf(elem: T): Int返回elem在序列中的索引,找到第一个就返回def indexOf(elem: T, from: Int): Int返回elem在序列中的索引,可以指定从某个索引处(from)开始查找,找到第一个就返回val a = Array(1,3,2,3,4)println(a.indexOf(3)) // 1println(a.indexOf(3,2)) // 3in
2020-10-29 15:27:42
201
原创 Scala Array常用方法(一)
Scala Array常用方法++def ++[B](that: GenTraversableOnce[B]): Array[B]合并集合,并返回一个新的数组,新数组包含左右两个集合对象的内容。 val a = Array(1,2) val b = Array(3,4) val c = a ++ b //c中的内容是(1,2,3,4)++:def ++:[B >: A, That](that: collection.Traversable[B])(implicit bf: C
2020-10-27 16:52:44
426
原创 scala伴生类和伴生对象
scala伴生类和半生对象//伴生类和伴生对象在同一文件中,名字相同//class类称为object的伴生类,object称为class的伴生对象class Person(uname:String,uage:Int){ //scala主构造方法,定义在类的头部 println("class 进入到Person的class类中") var name:String = uname var age:Int = uage private var address:String = "亚洲" d
2020-10-26 15:23:37
278
原创 scala模式匹配
scala模式匹配//模式匹配的基础语法 def match1(x:Char):Unit = x match { case 'A' => println("verygood") case 'B' => println("good") case 'C' => println("soso") case _ => println("work harder") } match1('D')//模式匹配中使用if守卫模式
2020-10-26 15:06:09
61
原创 scala 隐式转换
Scala 隐式转换1、隐式参数2、隐式方法3、隐式类当编译器第一次编译失败的时候,会在当前的环境中查找能让代码编译通过的方法,用于将类型进行转换,实现二次编译1、隐式参数普通方法或者函数中的参数可以通过implicit关键字声明为隐式参数,调用该方法时,就可以传入该参数,编译器会在相应的作用域寻找符合条件的隐式值。说明同一个作用域中,相同类型的隐式值只能有一个编译器按照隐式参数的类型去寻找对应类型的隐式值,与隐式值的名称无关。隐式参数优先于默认参数(优先级:传参>隐式参数>默
2020-10-23 14:02:58
78
原创 Scala入门基础
Scala入门基础Scala简介概述1.简介2.概述Scala变量与常量Scala数据类型层次结构1.数据类型层次结构2.字符串插值Scala条件控制1.语句2.条件语句返回值Scala循环控制Scala数组Scala元组Scala集合Scala简介概述1.简介Scala源自JavaScala构建在JVM之上Scala与Java兼容、互通Scala的优势多范式编程:面向对象编程、函数式编程表达能力强,代码精简大数据与ScalaSpark采用Scala语言设计提供的AP
2020-10-20 16:06:57
136
原创 IntelliJ IDEA安装scala插件并创建scala示例
IntelliJ IDEA安装scala插件并创建scala示例安装Scala插件和编译器安装Scala软件创建Scala工程安装Scala插件和编译器1、首先确定IntelliJ IDEA对应的scala版本在IDEA的File下找到Setting点进Setting,找到Plugins,点击左下方框得按钮在搜索框内查找scala,查看对应的版本号2、搜索网站https://plugins.jetbrains.com/plugin/1347-scala后,点击Version Histor
2020-10-19 14:41:11
229
原创 数据仓库理论概述
数据仓库理论概述1、数据仓库理论1.1学习数据仓库的目的1.2数据仓库的概念1.2.1面向主题1.2.2集成1.2.3非易失1.2.4随时间变化1.3数据仓库分层:2、数据仓库和数据库的区别2.1数据仓库和数据库的区别2.2OLTP和OLAP的区别3、数据仓库的架构3.1Inmon架构3.2Kimball架构3.3混合型架构3.4数据仓库的解决方案4、数据ETLETL工具5、数据仓库的建模5.1数据仓库模型构建5.1.1选择业务流程5.1.2声明粒度5.1.3确认维度5.1.4确认事实模型星型模型雪花模型
2020-10-09 17:11:50
152
原创 sqoop介绍及数据迁移
sqoop介绍及数据迁移1、sqoop概述2、sqoop常用命令3、sqoop数据迁移3.1从RDB导入数据到HDFS3.2从RDB导入数据到Hive3.3从RDB导入数据到HBase1、sqoop概述在上次的博客中,我们已经装好了sqoop,并且运行成功了,若是,有同学不清楚安装流程,请参考博客:sqoop安装及配置。那么sqoop到底是什么呢,作用是什么,我们现在就来看一看:Sqoop是一个用于在Hadoop和关系数据库之间传输数据的工具将数据从RDBMS导入到HDFSHDFS、Hiv
2020-09-29 19:11:35
266
原创 sqoop安装及配置
sqoop安装即环境配置一、sqoop 安装安装 sqoop 的前提是已经具备 Java 和 Hadoop、Hive、ZooKeeper、HBase 的 环境。1.1 下载并解压1.上传安装包 sqoop-1.4.6-cdh5.14.2.tar.gz 到虚拟机中2.解压 sqoop 安装包到指定目录tar -zxf sqoop-1.4.6-cdh5.14.2.tar.gz -C /opt/3.配置环境变量vi /etc/profile让配置文件生效source /etc/profi
2020-09-26 15:06:03
718
原创 phoenix理论、安装配置和对HBase的操作
phoenix理论和、安装配置和对HBase的操作phoenix理论概述应用场景架构SQL语法phoenix安装配置phoenix对Hbase的操作phoenix理论概述Phoenix简介构建在HBase上的SQL层使用标准SQL在HBase中管理数据使用JDBC来创建表,插入数据、对HBase数据进行查询Phoenix JDBC Driver容易嵌入到支持JDBC的程序中Phoenix无法代替RDBMS缺乏完整约束,很多领域尚不成熟Phoenix使HBase更易用应用
2020-09-26 14:22:25
157
原创 HBase基本命令
hbase基本命令用户权限:user_permission ['表名']grant '用户名','RWXCA'表:增:create '表名',{NAME=>'列簇名'},{NAME=>'列簇名'}删:disable '表名' ---> drop '表名'改:snapshot '表名','镜像名' clone_snapshot '镜像名','表名' delete_snapshot '镜像名'查:list行:put的时候:put '表名','行键','列
2020-09-25 16:16:58
83
原创 NoSQL综述及HBase基础
@[TOC](这里写目录标题NoSQLHBaseNoSQL什么是NoSQLNoSQL:not only SQL,非关系型数据库NoSQL是一个通用术语指不遵循传统RDBMS模型的数据库数据是非关系的,且不使用SQL作为主要查询语言解决数据库的可伸缩性和可用性问题不针对原子性或一致性问题为什么使用NoSQL互联网的发展,传统关系型数据库出现瓶颈高并发读写高存储量高可用性高扩展性低成本NoSQL与关系型数据库对比主要区别如下NoSQL的特点最终一
2020-09-25 16:13:45
213
原创 Hive函数及性能优化
Hive函数及性能优化Hive函数分类内置函数标准函数字符函数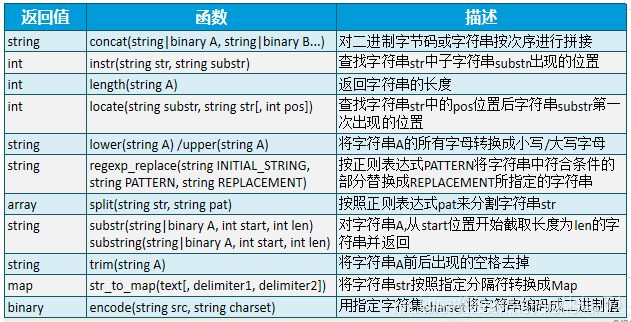类型转换函数数学函数![在这里
2020-09-25 15:14:58
370
原创 Hive窗口函数
Hive窗口函数概述排序聚合分析窗口定义概述窗口函数是一组特殊函数扫描多个输入行来计算每个输出值,为每行数据生成一行结果可以通过窗口函数来实现复杂的计算和聚合语法Function (arg1,..., arg n) OVER ([PARTITION BY <...>] [ORDER BY <....>] [<window_clause>])PARTITION BY类似于GROUP BY,未指定则按整个结果集只有指定ORDER BY子句之
2020-09-22 17:24:33
72
原创 Hive聚合函数
Hive聚合函数GROUP BYHAVING基础聚合高级聚合GROUP BYgroup by用于分组Hive基本内置聚合函数与group by一起使用如果没有指定group by子句,则默认聚合整个表除聚合函数外,所选的其他列也必须包含在group by中group by支持使用case when或表达式支持按位置编号分组:set hive.groupby.orderby.position.alias=true;案例:#执行失败(原因:除聚合函数外,所选的其他列也必须包含在group
2020-09-22 17:14:57
2086
原创 Hive数据排序
Hive数据排序order by(全局排序)sort by(分区内排序)/distribute bycluster by总结order by(全局排序)order by (asc|desc)类似于标准SQL只使用一个Reducer执行全局数据排序速度慢,应提前做好数据过滤支持使用case when或表达式支持按位置编号排序set hive.groupby.orderby.position.alias=true;案例:select name,id,info from employee
2020-09-22 17:06:18
97
原创 zeppelin安装配置
zeppelin安装配置一、下载安装包上传并解压修改配置文件四、启动zeppelin五、配置hive解释器六、使用Zepplin的hive解释器一、下载安装包http://zeppelin.apache.org/download.html进入页面后可以选择相应版本进行下载,我们这里选择zeppelin-0.8.1-bin-all.tgz上传并解压我们先将下载好的zeppelin包上传至Linux解压zeppelin包至/opt目录下tar -zxvf zeppelin-0.8.1-bi
2020-09-19 15:23:20
433
原创 hive查询语句中显示列名
要想在hive查询语句中显示列名,我们可以在hive命令行中手动开启:set hive.cli.print.header=true;但是这条命令有个弊端,那就是命令只能在当前会话有效,退出hive就失效,而且会显示表名,使得列名会十分冗长,所以我们可以使用下面的方法让命令自动生效,而且不显示表名。在hive/conf/hive-site.xml配置文件中添加下面的内容。<property> <name>hive.resultset.use.unique.column.na
2020-09-17 18:58:38
1338
原创 hive 支持的文件格式
hive 支持的文件格式hive支持的文件格式TEXTFILE 格式SEQUENCEFILE 格式RCFILE 文件格式hive支持的文件格式Hive文件存储格式包括以下几类:1、TEXTFILE2、SEQUENCEFILE3、RCFILE4、ORCFILE(0.11以后出现)其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理。SEQUENCEFILE,RCFILE,ORCFILE格式的表不能直接从本地文件导入数据,数据要
2020-09-17 16:24:48
893
原创 Apache Hive基础
Apache Hive基础Hive理论基础Hive操作Hive理论基础1、什么是Hive?基于Hadoop的数据仓库解决方案将结构化的数据文件映射为数据库表提供类sql的查询语句HQL(Hive Query Language)Hive让更多人使用HadoopHive成为Apache顶级项目Hive始于2007年的Facebook官网:http://hive.apache.org2、Hive的优势和特点提供了一个简单的优化模型HQL类SQL语法,简化MR开发
2020-09-16 18:25:29
234
![]()
空空如也
![]()
空空如也
TA创建的收藏夹 TA关注的收藏夹
TA关注的人